Web Archiving: Why? How? Why?
Erik Hetzner
ehetzner@plos.org
What is web archiving?
PLOS 2003
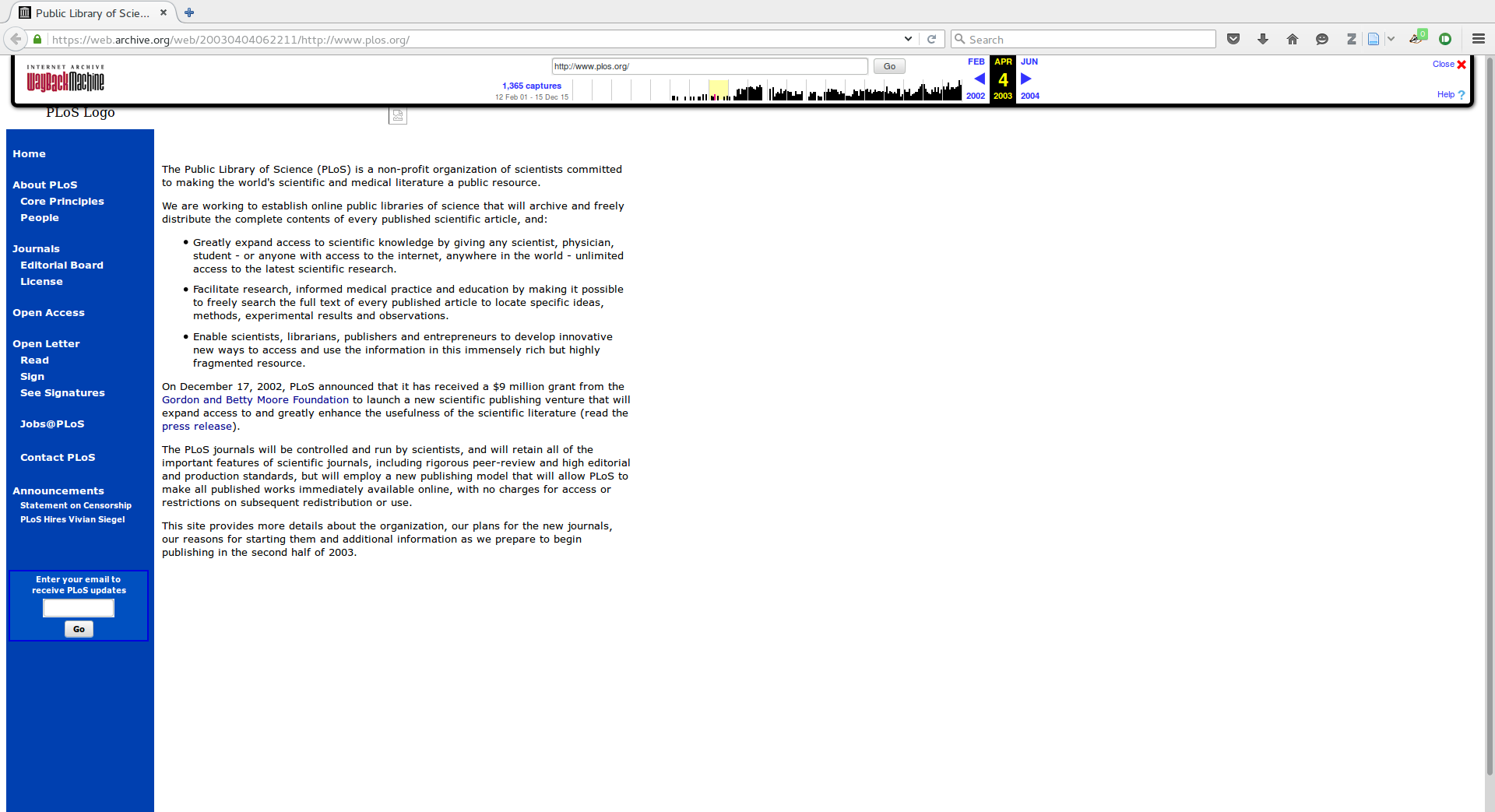
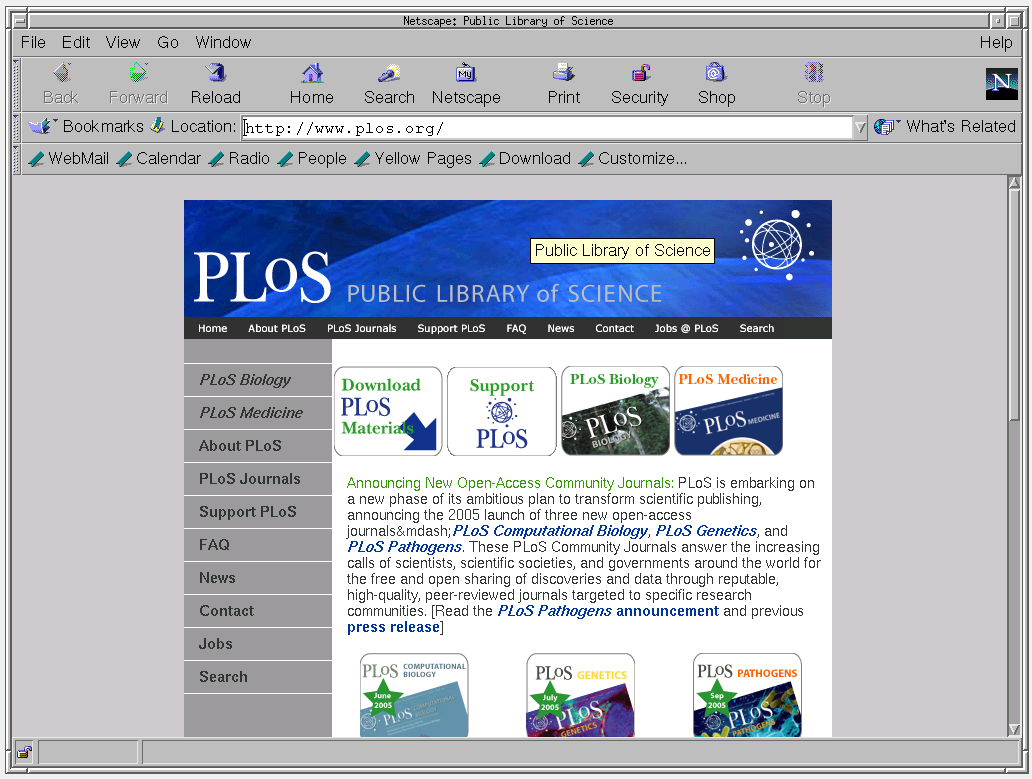
PLOS 2004
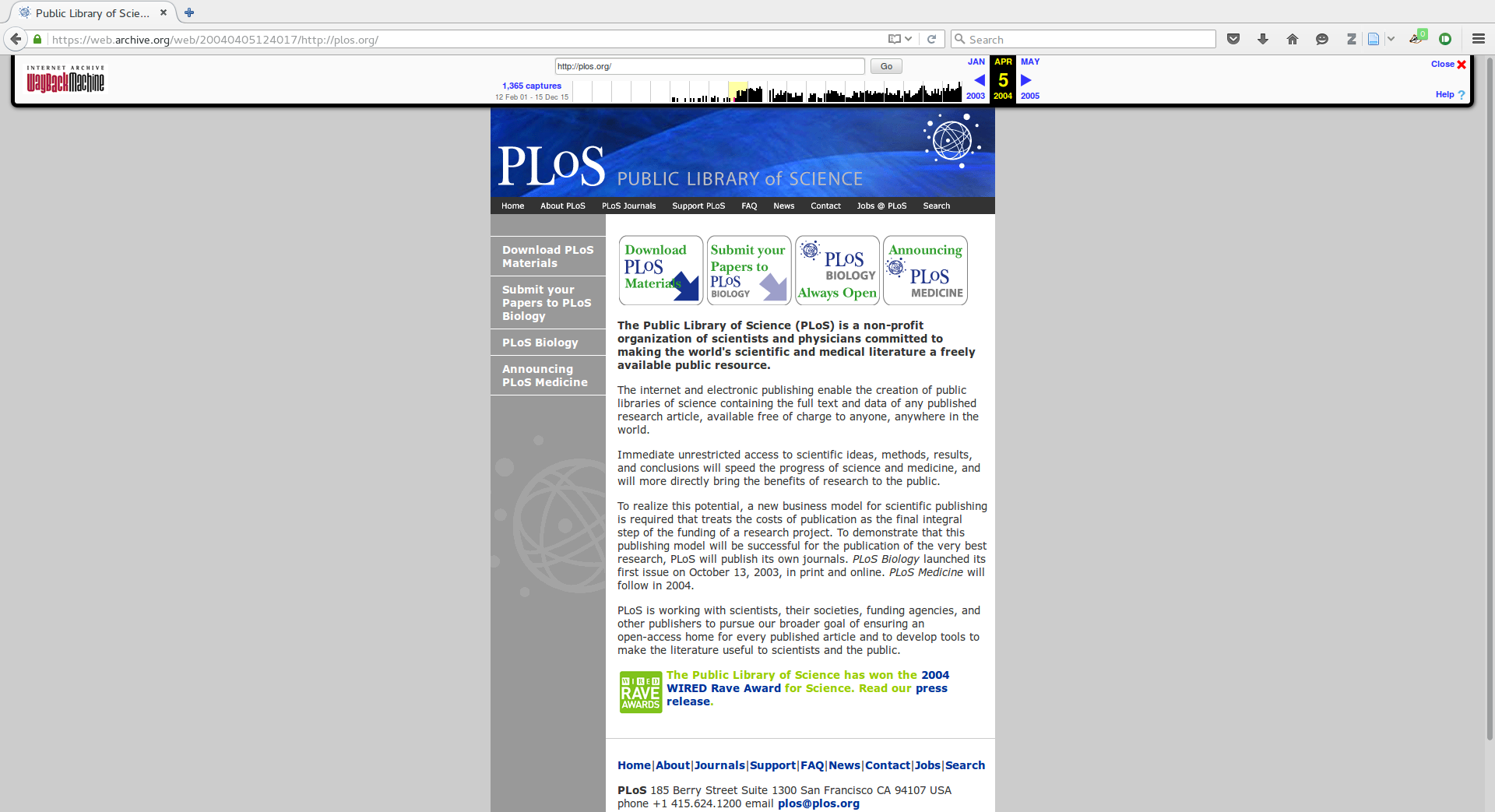
PLOS 2006
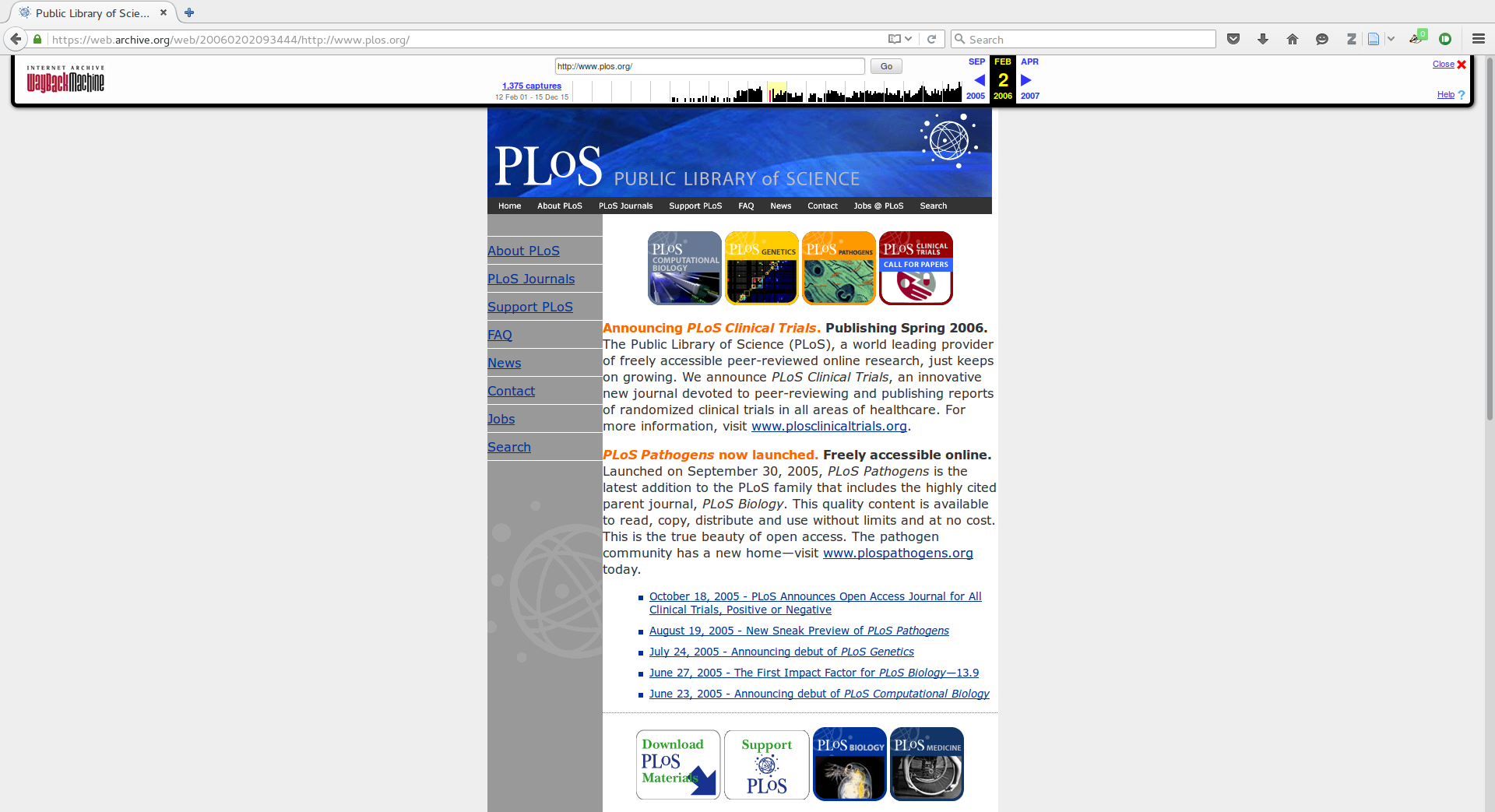
PLOS 2007
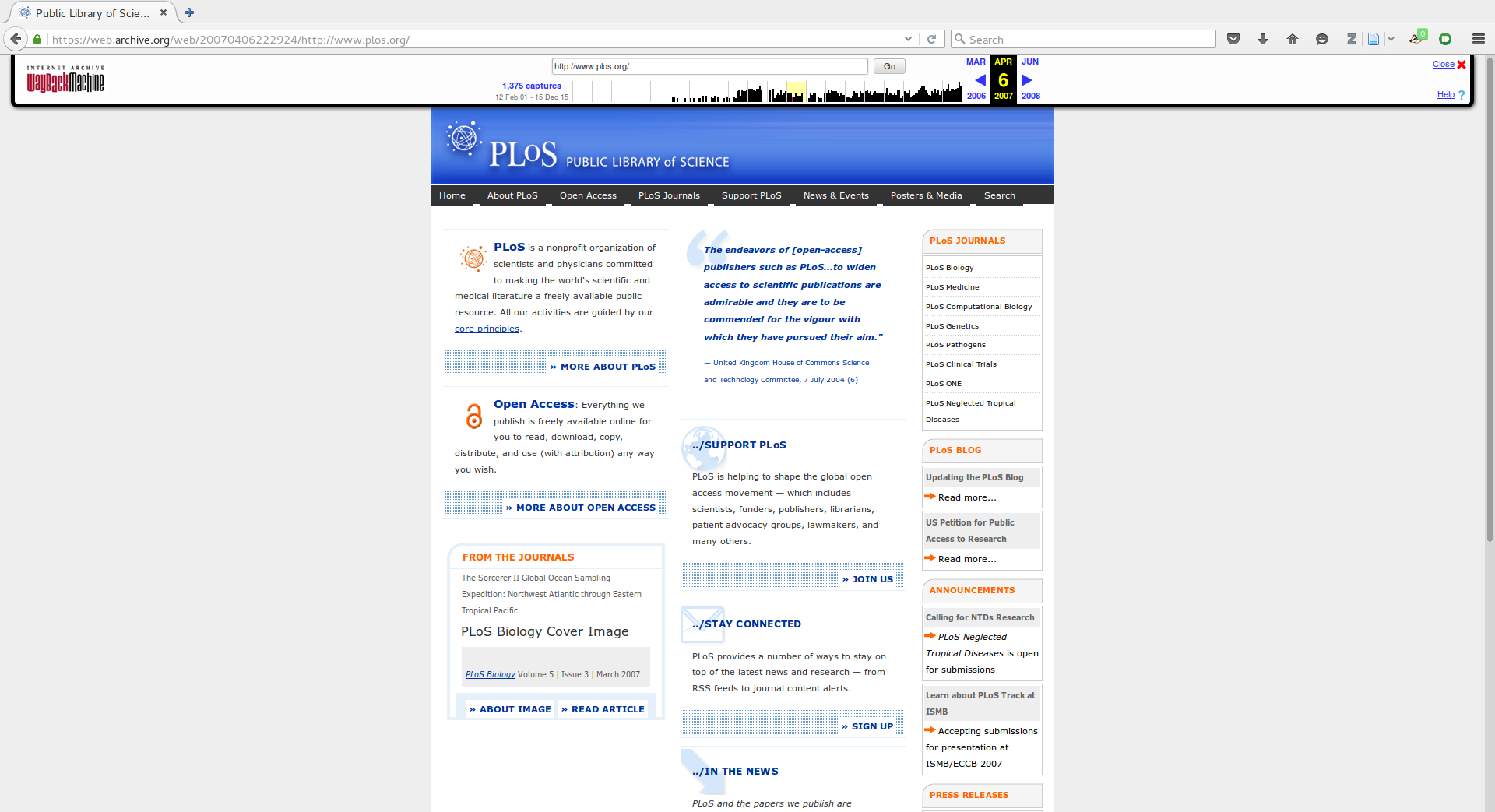
PLOS 2011
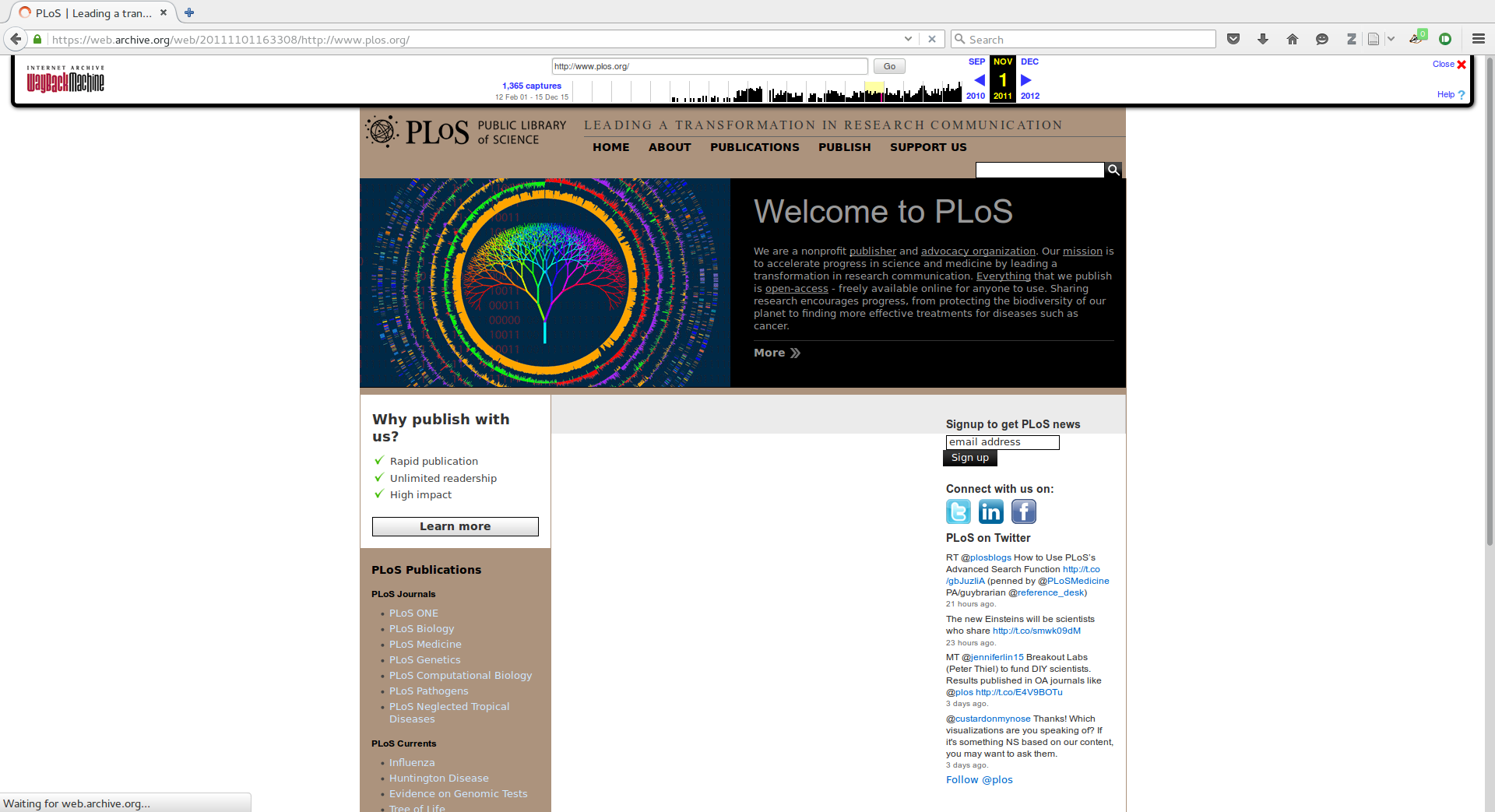
PLOS 2014
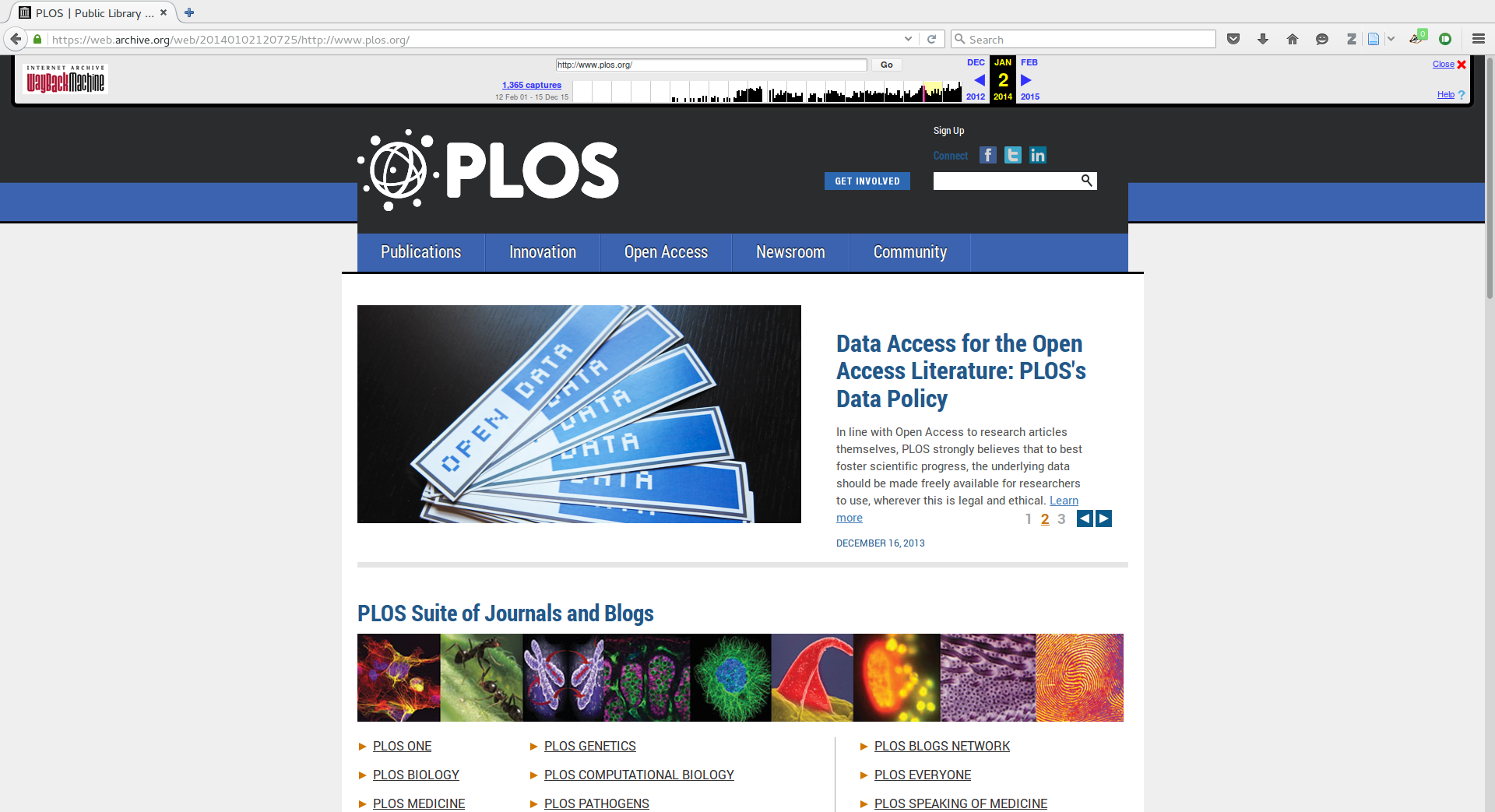
PLOS 2015
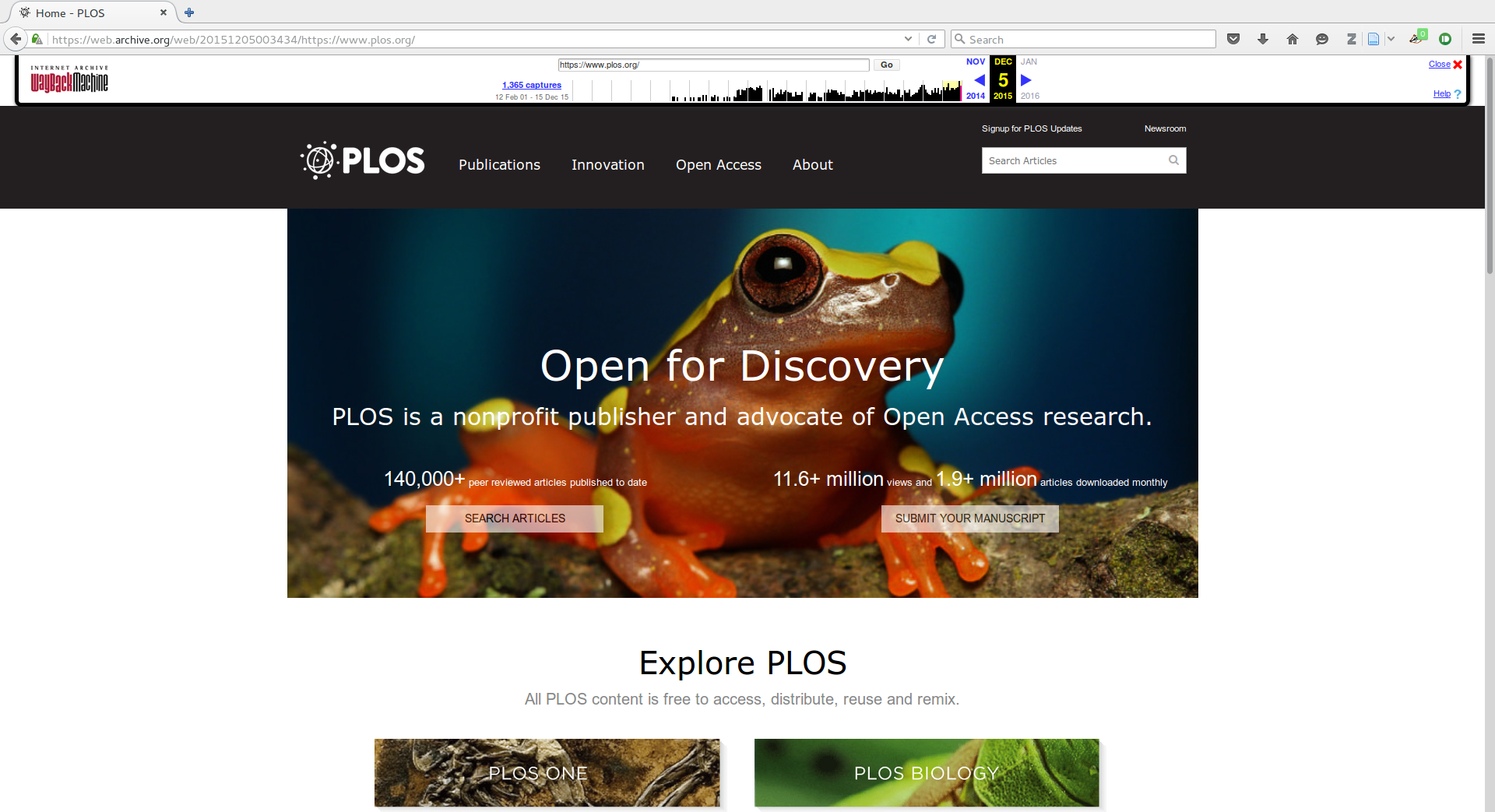
Not just screenshots
- Web archiving allows you to browse the web, as it was
Why?
- The web is now part of the historical & scientific record
Why?

- J Clerk Maxwell (1865) A Dynamical Theory of the Electromagnetic Field Philosophical Transactions of the Royal Society of London 155: 459-512. 10.1098/rstl.1865.0008
Why?

- PR Smeesters, A Vergison, D Campos, E de Aguiar, VYM Deyi, L Van Melderen (2006) Differences between Belgian and Brazilian Group A Streptococcus Epidemiologic Landscape. PLOS One 1(1): e10. 10.1371/journal.pone.0000010
Why?
Why?
Link rot
- “50% of the URLs within U.S. Supreme Court opinions suffer reference rot”
- JL Zittrain, K Albert, L Lessig (2013) Perma: Scoping and Addressing the Problem of Link and Reference Rot in Legal Citations Harvard Public Law Working Paper No. 13-42. 10.2139/ssrn.2329161
Content changing
- White House web documents listing the “Coalition of the Willing” changed, but dates remained the same
- “The text of three of these five documents was altered at some point after their initial release, even though in most cases the documents still retained their original release dates and were presented as unaltered originals. These alterations to the public record changed the apparent number of countries making up the coalition, as well as the names of countries in the coalition.”
- S Althaus, K Leetaru Airbrushing History, American Style. http://www.clinecenter.illinois.edu/research/affiliated/airbrush/
But how can that work?
- It‘s actually pretty simple.
- Crawl the web
- Replay the crawls
Crawling
- Largely standard web crawling
Procedure
- Initialize queue of URLs with seeds
- For each URL in queue
- Download URL and save the response
- Extract all the other URLS and add to queue
Storing
- Store the response (and sometimes the request):
HTTP/1.1 200 OK Date: Wed, 30 Apr 2008 20:48:28 GMT Server: Apache/2.0.54 (Ubuntu) PHP/5.0.5-2ubuntu1.4 mod_ssl/2.0.54 OpenSSL/0.9.7g Last-Modified: Mon, 16 Jun 2003 22:28:51 GMT ETag: "34dc-67e-2ed02ec0" Accept-Ranges: bytes Content-Length: 1662 Connection: close Content-Type: image/jpeg FF D8 FF E0 00 10 4A …
Replay
- User requests http://www.plos.org/ at 2004-10-14T08:46:58 via http://web.archive.org/20041014084658/http://www.plos.org/
- Do we have a copy?
- Yes: Send it to user
- Rewrite all links, embedded images, stylesheets, etc. with a prefix, e.g. http://www.plosmedicine.org/ becomes http://web.archive.org/web/20041014084658/http://www.plosmedicine.org/
- No: Find the closest copy of http://www.plos.org/ in time and redirect
- Yes: Send it to user
Replay
- You can see how this would work, if all URLs (for CSS, JS, images, etc.) are rewritten
Storage
- Concatenate the results into ~100MB files
http://www.archive.org/index.php 207.241.229.39 20080430204826 text/html 29000 HTTP/1.1 200 OK Date: Wed, 30 Apr 2008 20:48:25 GMT […] http://www.archive.org/flv/flv.js?v=1.34 207.241.229.39 20080430204833 application/x-javascript 16969 HTTP/1.1 200 OK Date: Wed, 30 Apr 2008 20:48:32 GMT […]
- compress the results
Storage
- Store these file on a bunch of disks
Storage
- Index the files with the URL (in sortable order), the timestamp, the filename it is stored in, and the byte-offset into the file.
… org,archive)/index.php 20080430204826 file1.arc.gz 8643 … org,archive)/flv/flv.js?v=1.34 20080430204833 file2.arc.gz 5130 … …
Tricky engineering
Storage
- Storage
- Need to store data in the petabyte range
- Deduplication
Leakage
- “Leak”s into the live web
- Rewriting all URLs is hard
- JavaScript makes it harder
Full-text indexing
- Full-text indexing
- So much content
- What is relevant when you have many copies of the same page?
Brief history
- Wayback Machine (Internet Archive) began in 1996.
- Now contains 9PB of data, growing by 20TB/week.
- Later, other organizations got involved.
- Many countries have “legal deposit” laws. These laws require publishers to deposit items in a library.
- These countries have often decided that these laws apply to the national internet
- Examples: France, Iceland, Denmark, Norway, Portugal
Copyright
- Section 108
- Section 108 of the Copyright Act provides limitations on exclusive rights for libraries and archives
- Section 108 study group has determined that libraries and archives have the right to preserve web content
- Opt out
- Government entities, political parties and campaigns cannot opt out
- Section 108 Study Group (2008) The Section 108 Study Group report.
Architecture
- The same architectural principles that make the scalable, proxyable web possible make web archiving possible
- Think of web archiving as “proxy”ing the web, with time travel
REST
- Stateless
- No client content stored on the server
- This means that we need not emulate a server in order to recreate the user experience
REST
- Code on demand
- Client side code (javascript)
- Allows us to archive client behavior
REST
- Identification of resources
- Resources have globally unique identifiers
- We needn’t keep track of whether this is document “1” from site A or document “1” from site B
REST
- Self-descriptive messages
- Every server request-response is self-sufficient
- We do not need to archive context
REST
- Hypermedia as the engine of application state
- Each document contains within itself “links” to next client state
- For each page, we have the next globally unique next states for the client
- RT Fielding (2000) Architectural styles and the design of network-based software architectures. UCI.
BBS
- Stateful
- Client state stored on server
- All code on server
- No identification of resource
- Navigate to locations via interaction
- Context dependent messages
- Every interaction depends on all previous interactions
Next steps
Emulation
Social media
- Twitter, etc.
- Often customized for the user
- Highly dynamic
Memento
- Integrating the concept of “time” into web request
- Works with Wikipedia, Internet Archive, etc.
- http://mementoweb.org/
Catching up with the changing web
- HTML5
- Single page applications
- etc.
Scholarly archiving
PLOS
- Work with http://perma.cc/ to ensure that all web references in our articles are preserved